Seguramente sabrás de mi…Me presento: mi nombre es Machine y mi apellido Learning, en cuanto a mi edad, algunos me datan allá por mediados del siglo XX. Pero, ¿quién soy? Más allá de lo que se diga sobre mí en internet, me gusta pensar que soy la principal disciplina de la que dispone el ser humano para extraer valor del mundo que le rodea.
Mi historia no se entiende sin las matemáticas, fui creciendo de la mano de los nuevos descubrimientos en el área como las redes neuronales, que simulan las conexiones del cerebro humano, y los primeros algoritmos de agrupación. Hitos como la primera vez que una máquina bate a un campeón de ajedrez, en el año 1997, y a los principales campeones de un concurso televisivo en 2011, ambos de la mano de la compañía estadounidense IBM, fueron dando forma al cuerpo del que hoy dispongo.
Todos estos algoritmos matemáticos que me componen pueden dividirse en dos grandes grupos: técnicas de aprendizaje supervisado y técnicas de aprendizaje no supervisado.
Machine Learning con aprendizaje supervisado
Las técnicas englobadas dentro de este tipo de aprendizaje tienen como objetivo explicar el comportamiento de algún suceso concreto dentro de tu conjunto de datos. Las principales características de este tipo de modelos son que existen clases o etiquetas asignadas a cada observación, y que constan de dos fases: la fase de entrenamiento y la fase de validación.
Antes de pasar a detallar ambas fases, veamos una posible aplicación de este tipo de modelos. Imaginad que ofrecéis un determinado servicio a un grupo de clientes y tenéis una serie de datos recogidos sobre ellos y su relación con tu empresa (estos datos son conocidos como datos de entrada), así como si a día de hoy siguen contratando o no vuestros servicios (a este valor le llamaremos clase o etiqueta). Con un modelo de aprendizaje supervisado es posible predecir el abandono de un cliente antes de que esto suceda y conocer las variables que influyen en este hecho, pudiendo así actuar con antelación.
Modelo de clasificación binomial:
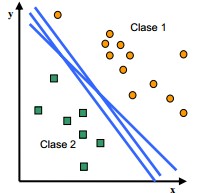
Fase de entrenamiento
Es en esta fase donde se entiende el nombre de este tipo de técnicas. Para elaborar tu modelo de Machine Learning de aprendizaje supervisado has de disponer de un conjunto de datos etiquetado en el que puedas supervisar el comportamiento de la variable a predecir. En esta fase se utiliza la mayor parte de tu conjunto de datos (normalmente un 70%) para entrenar al modelo. De esta manera, es capaz de aprender acerca de las causas que determinan el comportamiento de la etiqueta.
Fase de validación
Una vez construido, antes de aplicar tu modelo es muy importante validarlo. Esta fase se realiza sobre un conjunto de datos que todavía no se conocen (que no hayan entrado dentro de la fase de entrenamiento), pero de los que sí dispongas del valor de la clase o etiqueta, para evaluar su porcentaje de acierto. Es por esto por lo que nos reservamos una parte del conjunto de datos inicial (normalmente un 30%). Además de para garantizar la validez del modelo, este proceso nos ayuda a evitar un sobreajuste, es decir, evitar que éste se ajuste muy bien a tus datos, pero tenga un mal rendimiento a la hora de predecir nuevos resultados.
Machine Learning y el aprendizaje no supervisado
Este tipo de técnicas, a diferencia de los algoritmos de aprendizaje supervisado, no buscan conocer, predecir o clasificar el valor de las variables de un conjunto de datos. El objetivo va más allá: buscan elevarte a un nivel superior con respecto a tus datos y ser capaz así de encontrar las relaciones o la regularidad oculta que no puede ser intuida con un primer análisis descriptivo.
Las técnicas más conocidas de agrupación son conocidas como análisis clúster. En contraste a las técnicas supervisadas, estos modelos se caracterizan por no necesitar de clases o etiquetas asignadas a cada observación, ni tampoco existe una fase de entrenamiento.
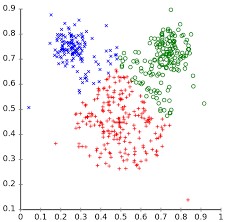
Siguiendo con el ejemplo del grupo de clientes, suponed ahora que lo que queréis es detectar grupos homogéneos de clientes para poder ofrecerles ofertas diferenciadas dependiendo de sus características. Estas técnicas calculan las distancias entre observaciones (en este caso clientes) mediante distintas técnicas y encuentran grupos próximos (se minimizan dichas distancias), de manera que el resultado obtenido es la división de tus datos en distintos grupos o clústers. Mediante el análisis de estos grupos seremos capaces de detectar características o comportamientos comunes y poder así personalizar la atención ofrecida al cliente.
Tras este breve repaso a mi pasado y el esqueleto que me compone en el presente, sólo me queda por decir que mi futuro es prometedor. Para ello, cuento con dos grandes colaboradores que son mi principal motor: el gran volumen de datos generados y los avances computacionales.
¡Me aventuro a predecir que volveremos a vernos pronto con nuevos avances!
Si queréis ampliar información sobre este tema y conocer el software utilizado para llevarlo a la práctica, podéis descargaros la grabación del Webinar IBM Watson: herramientas para el análisis cognitivo y el análisis predictivo y Watson Analytics: analiza y predice los datos de tu negocio.
Artículo redactado por Lidia Orellana



Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.